Spark History Server
Overview
The Stackable Spark-on-Kubernetes operator runs Apache Spark workloads in a Kubernetes cluster, whereby driver- and executor-pods are created for the duration of the job and then terminated. One or more Spark History Server instances can be deployed independently of SparkApplication jobs and used as an end-point for spark logging, so that job information can be viewed once the job pods are no longer available.
Deployment
The example below demonstrates how to set up the history server running in one Pod with scheduled cleanups of the event logs. The event logs are loaded from an S3 bucket named spark-logs and the folder eventlogs/. The credentials for this bucket are provided by the secret class s3-credentials-class. For more details on how the Stackable Data Platform manages S3 resources see the S3 resources page.
---
apiVersion: spark.stackable.tech/v1alpha1
kind: SparkHistoryServer
metadata:
name: spark-history
spec:
image:
productVersion: 3.5.2
logFileDirectory: (1)
s3:
prefix: eventlogs/ (2)
bucket: (3)
inline:
bucketName: spark-logs
connection:
inline:
host: test-minio
port: 9000
accessStyle: Path
credentials:
secretClass: history-credentials-class
sparkConf: (4)
nodes:
roleGroups:
default:
replicas: 1 (5)
config:
cleaner: true (6)| 1 | The location of the event logs. Must be a S3 bucket. Future implementations might add support for other shared filesystems such as HDFS. |
| 2 | Folder within the S3 bucket where the log files are located. This folder is required and must exist before setting up the history server. |
| 3 | The S3 bucket definition, here provided in-line. |
| 4 | Additional history server configuration properties can be provided here as a map. For possible properties see: https://spark.apache.org/docs/latest/monitoring.html#spark-history-server-configuration-options |
| 5 | This deployment has only one Pod. Multiple history servers can be started, all reading the same event logs by increasing the replica count. |
| 6 | This history server will automatically clean up old log files by using default properties. You can change any of these by using the sparkConf map. |
Only one role group can have scheduled cleanups enabled (cleaner: true) and this role group cannot have more than 1 replica.
|
The secret with S3 credentials must contain at least the following two keys:
-
accessKey- the access key of a user with read and write access to the event log bucket. -
secretKey- the secret key of a user with read and write access to the event log bucket.
Any other entries of the Secret are ignored by the operator.
Spark application configuration
The example below demonstrates how to configure Spark applications to write log events to an S3 bucket.
---
apiVersion: spark.stackable.tech/v1alpha1
kind: SparkApplication
metadata:
name: spark-pi-s3-1
spec:
sparkImage:
productVersion: 3.5.2
pullPolicy: IfNotPresent
mode: cluster
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: s3a://my-bucket/spark-examples.jar
s3connection: (1)
inline:
host: test-minio
port: 9000
accessStyle: Path
credentials:
secretClass: s3-credentials-class (2)
logFileDirectory: (3)
s3:
prefix: eventlogs/ (4)
bucket:
inline:
bucketName: spark-logs (5)
connection:
inline:
host: test-minio
port: 9000
accessStyle: Path
credentials:
secretClass: history-credentials-class (6)
executor:
replicas: 1| 1 | Location of the data that is being processed by the application. |
| 2 | Credentials used to access the data above. |
| 3 | Instruct the operator to configure the application with logging enabled. |
| 4 | Folder to store logs. This must match the prefix used by the history server. |
| 5 | Bucket to store logs. This must match the bucket used by the history server. |
| 6 | Credentials used to write event logs. These can, of course, differ from the credentials used to process data. |
History Web UI
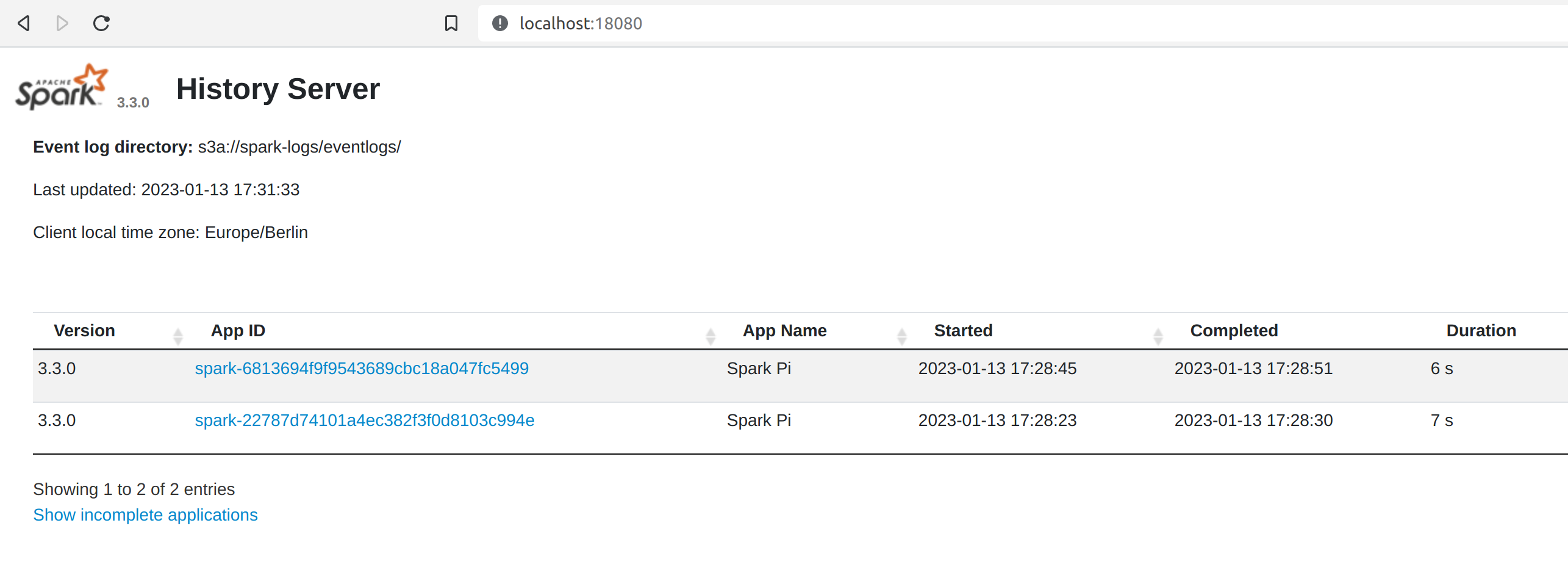
To access the history server web UI, use one of the NodePort services created by the operator. For the example above, the operator created two services as shown:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
spark-history-node NodePort 10.96.222.233 <none> 18080:30136/TCP 52m
spark-history-node-cleaner NodePort 10.96.203.43 <none> 18080:32585/TCP 52mBy setting up port forwarding on 18080 the UI can be opened by pointing your browser to http://localhost:18080:
Configuration Properties
For a role group of the Spark history server, you can specify: configOverrides for the following files:
-
security.properties
The security.properties file
The security.properties file is used to configure JVM security properties. It is very seldom that users need to tweak any of these, but there is one use-case that stands out, and that users need to be aware of: the JVM DNS cache.
The JVM manages its own cache of successfully resolved host names as well as a cache of host names that cannot be resolved. Some products of the Stackable platform are very sensible to the contents of these caches and their performance is heavily affected by them. As of version 3.4.0, Apache Spark may perform poorly if the positive cache is disabled. To cache resolved host names, and thus speeding up queries you can configure the TTL of entries in the positive cache like this:
nodes:
configOverrides:
security.properties:
networkaddress.cache.ttl: "30"
networkaddress.cache.negative.ttl: "0"| The operator configures DNS caching by default as shown in the example above. |
For details on the JVM security see https://docs.oracle.com/en/java/javase/11/security/java-security-overview1.html